


How does ChatGPT work, anyway?
How does ChatGPT work, anyway?
Get the most out of ChatGPT by understanding how it works.


About a year before leaving Google, I got early access to their experimental chatbot. Though charmed by its cute messages, I overlooked the enormity of what I was playing with. “What’s the practical purpose of conversing with a robot?” I pondered, dismissing it.
What a lack of imagination!
It was only in September of last year, when a friend and I toyed with startup ideas, that the significance hit home. This “GPT-3 thing” – created by OpenAI – was amazing for business applications. We were soon generating complex business documents for a few measly cents.
It was as if someone had invented electricity, the steam engine and the printing press, all at once. (No doubt you had your own similar ‘aha!’ moment!)
Then ChatGPT launched, and all hell broke loose.
In this article I want to explain how Large Language Models (LLMs) work. I’ll explain it from a very high level, glossing over unnecessary detail. By the end, you’ll understand how to work around the limitations of ChatGPT to get the most out of it.
If nothing else, you’ll be able to impress your friends at your next dinner party.
ChatGPT is like a giant spreadsheet
The first thing to understand is that ChatGPT doesn’t actually “think” in written text. It thinks in tokens, which is a fancy way of saying numbers. The word cat, for example, would tokenize to the number 9246.1
An LLM can thus be imagined as a giant calculator, or a spreadsheet. It takes in some text, converts the text to numbers and does some math. The output is just more numbers, which are converted back to text.
A large artificial neural network (“neural net”) performs the “calculation” part. This comprises of layers of neurons, constructed in a lattice-like structure:

But, to make this easier to understand, let’s try to visualize this as though it’s a spreadsheet. Can you see the columns and rows?
The first column – the input layer – is, unsurprisingly, where your input goes. If you ask ChatGPT to, “write me a poem about a cat”, this would tokenize to [13564, 502, 257, 21247, 546, 257, 3797].
Each token will feed into a cell in our input layer column:2

Then comes the hidden layers. This is the real brain of the LLM.
ChatGPT has as many as 96 layers, or more, comprising some 175 billion neurons. Thus, in our little spreadsheet, let’s pretend we have 96 more columns, with a total of 175 billion cells underneath!
Hidden layer neurons are also referred to as parameters. If you hear someone say “this is a 8B parameter model”, they’re talking about the number of hidden layer neurons, or cells in our spreadsheet.
But what exactly are parameters? Think of them like a little calculator – or a spreadsheet formula. Inside we store a magic number, called a weight. This parameter will receive input from downstream connections and multiply those inputs by its weight. The output is then sent to any connected cells in the next column, and the process repeats.
In the beginning we won’t know what our weights should be, so we might initialize them with random numbers:
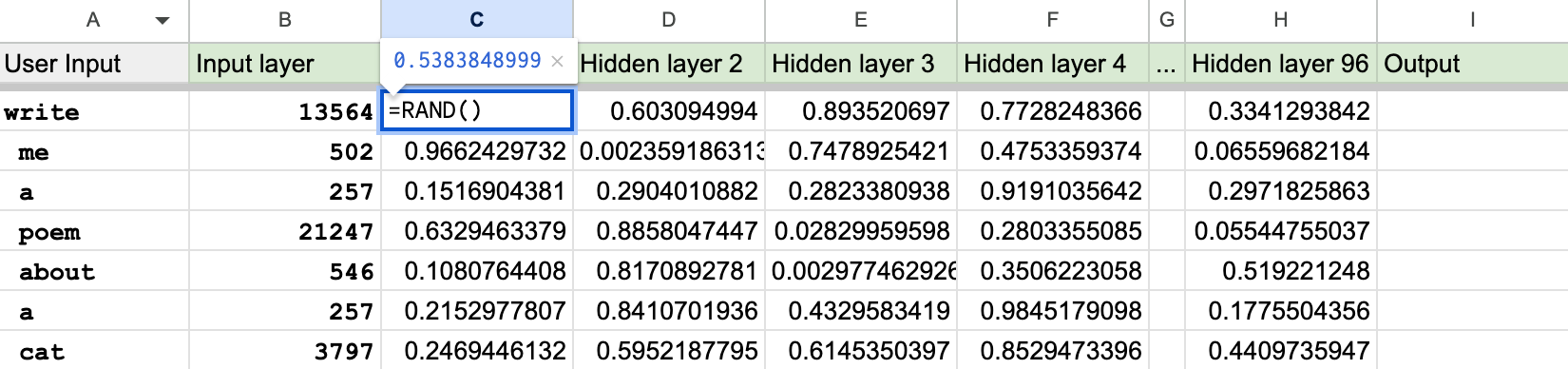
Now we need training data so we can discover the best possible weights for our model. This is what machine learning is all about – the machine is trying to learn its weights.
To train ChatGPT, we’ll start by downloading a large copy of the web.3 Our initial goal will be to train our neural net to predict the next word on the internet.
To begin training, let’s say we show our neural net the first half of a random sentence from Wikipedia. It must then try to guess the next word. Because the weights are still random, the output will be complete gibberish. But we know the actual answer, so we can backpropagate how close or far it was. Once the weights are adjusted, it can try again. And then again. And again.
It’s a brute-force game of “Hunt the Thimble” (aka “Hot and Cold”). In mathematics, we know this technique as gradient descent.
This stage of training for ChatGPT will cost millions of dollars of compute time and take many weeks to complete.
Being able to predict the next word on the internet is jolly good, but it’s actually not that useful. It’s just the first step.
We now need to teach it how to do things like write poems, or summarize text. The good news is our neurons are now primed to do this kind of work. They already have a very good statistical model of how humans write. We can use a much smaller subset of curated data to teach these more specialized tasks.
For example, let’s say we want to teach it how to summarize documents. We would create a document (our prompt) and a summary of that document (the completion). This would be included in our training data. We’ll then have the neural net adjust some of its weights until it can generate the summary from the prompt. Repeat over many task types, and voilà, ChatGPT.
(I can recommend this wonderful talk by Andrej Karpathy if you’re interested to learn more of the technical detail.)
By now, you should be getting the idea on how this all works. ChatGPT is a large statistical model – nothing more than a fancy abacus on steroids. It completes tasks by predicting the next token in a sequence.
Now, let’s explore the limitations of this design and how we can best use ChatGPT.
What are the design limitations of ChatGPT?
Due to the training methods discussed above, certain key implications arise:
LLMs often fabricate data (in other words, they “hallucinate”).
LLMs predict the next token using statistics without questioning the correctness of their thinking. Thus, ChatGPT may produce entirely false information. (A lawyer recently faced fallout when ChatGPT invented fictitious precedents.)You need to ask them to think through a problem.
Because they lack higher-order thinking, you need to demand they think through problems. This is called prompt engineering. You want to slow the output down so the LLM has time to reason through the problem. Here are some good prompt hacks – according to Andrej Karpathy – you can try:“Let’s think step by step…”
“Let’s work this out in a step by step way to be sure we have the right answer…”
“You are a leading expert on this topic…”
“You have an IQ of 120…”
They don’t know what they don’t know.
ChatGPT won’t know about recent events or updates not included in its training data. You need to supply ChatGPT with all the information and tools it needs to do its job at query time. The paid version of ChatGPT, for example, includes a plugin with internet access. There are also open source efforts, e.g. LangChain, that can use tools like calculators.You’re not talking to Artificial General Intelligence.
ChatGPT is very good at outputting intelligent text, but it’s not sentient. As discussed above, it’s nothing more than an impressive statistical token sequencer. Once trained, there’s no self-learning “memory”, or sensory machines to interpret external phenomena. But let’s leave that to the philosophers to argue about.4
What am I working on now?
After playing with GPT-3 for many months, I realized hallucination was a major problem. I decided to build a chatbot that leveraged only the comprehension skills of ChatGPT. It was a lot of fun to build, but now I need to find some customers for it – a task I don’t really enjoy.
In a future post I’ll cover how my chatbot service Mottle works, including introducing the concept of embeddings - which are extremely cool (I’m a geek!) with many commercial applications.
~Mike
If you’re interested, OpenAI has a great tokenizer tool that visualizes this for you.
Keen observers might notice that “cat” here has been tokenized to [3797] and not [9246] as it was previously above. This is because, when used in a sentence, we need to account for spaces. The token [3797] also includes the preceding space (highlighted in green).

For example, CommonCrawl and The Pile
Searle argues, “manipulation of formal symbols, is not the same as thinking”. I’m not sure if I entirely buy that, because at some point manipulation of formal symbols must become thinking, but I don’t think we’re there yet.